Dein Lesen, als ein Wissensgraph
Du liest nicht in Silos — warum es dann so speichern? Pith destilliert alles, was du sicherst, zu einem Wissensgraphen. Und genau die Verbindungen, die er sichtbar macht, sind der Mehrwert.
In short
Pith baut aus deinen Bookmarks ein zitiertes Wiki und verbindet die destillierten Konzepte zu einem Wissensgraphen. Du suchst ihn semantisch — du tippst ein Thema, und verwandte Konzepte leuchten auf, auch wenn das exakte Wort nie vorkommt — und klickst einen Knoten an, um seine Wiki-Seite zu öffnen.
The team behind Pith Lab
Du liest nicht auf einer Spur. In einer einzigen Woche liest du eine regulatorische Konsultation, den Earnings Call eines Wettbewerbers, ein Market Sizing für eine ganz andere Branche und ein langes Memo zu einem Deal, der vielleicht zustande kommt. Danach legst du jedes Stück irgendwo ab — ein Ordner, ein Tag, ein Tab, den du nie wieder öffnest — und die Verbindungen dazwischen verdampfen leise.
Das ist der Verlust. Nicht das Lesen. Die Nachbarschaften.
Der ganze Sinn, breit gelesen zu haben, ist, dass zwei Dinge, die du drei Wochen auseinander gelesen hast, sich als dasselbe entpuppen. Der neue Markt eines Kunden steht unter der Regulierung, die du für ein anderes Mandat überflogen hast. Der Deal, den du gerade bewertest, hat einen Präzedenzfall, vergraben in einem Branchen-Scan, den du gespeichert und vergessen hast. Du kannst nur darauf reagieren, wenn du es siehst.
Der Graph ist genau die Verbindung, die du sonst verpasst
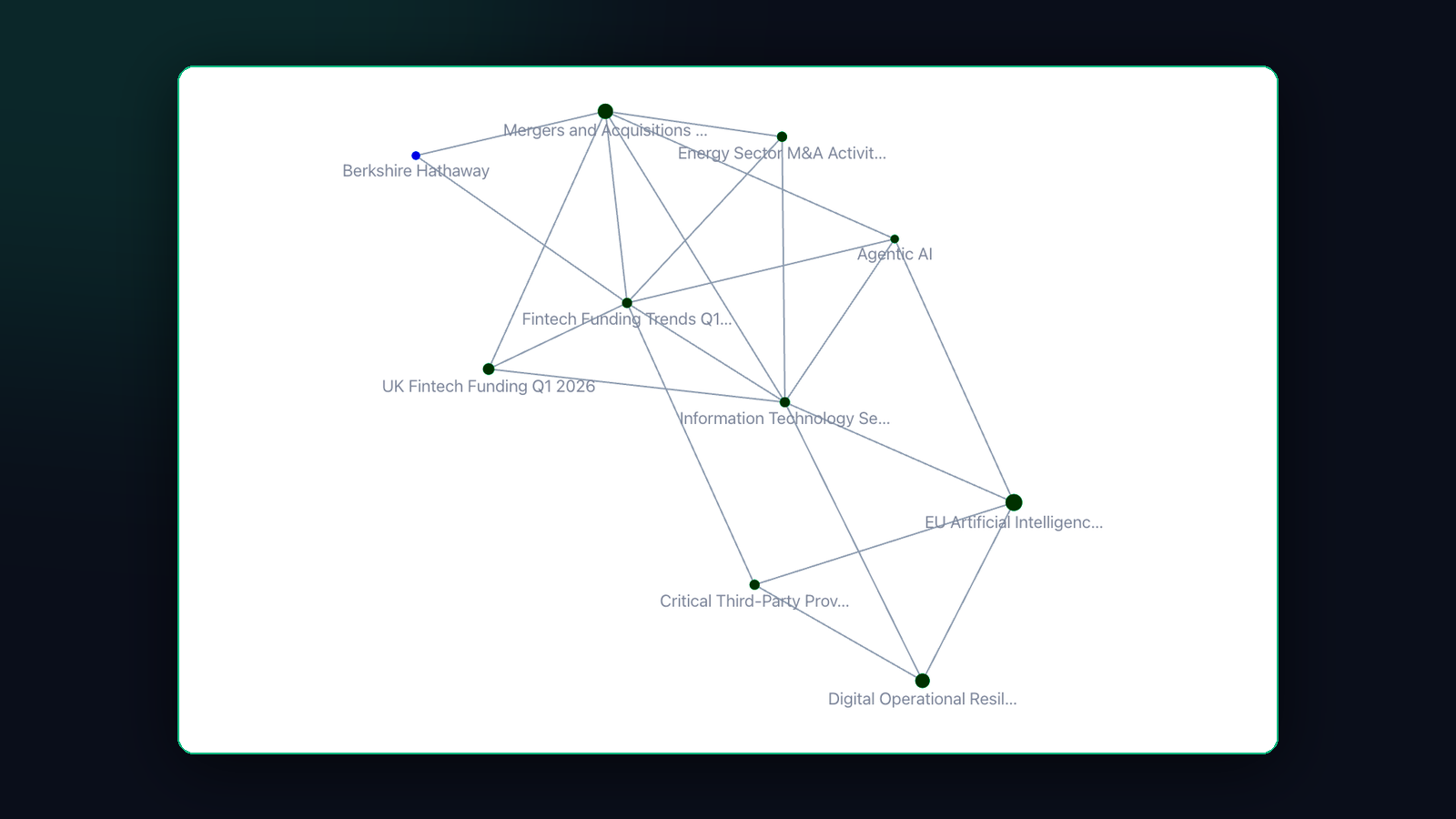
So funktioniert Pith. Du speicherst, was du liest — drei Sekunden, keine Ablage-Entscheidung. Pith destilliert jeden Save zu Konzepten und setzt daraus ein zitiertes Wiki zusammen, das du nie schreiben musstest. Dann kommt der entscheidende Teil: Es verbindet diese Konzepte zu einem Wissensgraphen.
Kein Graph pro Projekt. Kein Graph pro Kunde. Ein Graph, über alles, was du gelesen hast.
Jeder Knoten ist ein Konzept. Jede Kante ist ein echtes gemeinsames Auftauchen — diese beiden Ideen standen in deinem tatsächlichen Lesen nebeneinander, nicht in irgendeiner generischen Ontologie. Wenn du den Graphen öffnest, schaust du also nicht auf eine Tag-Wolke. Du schaust auf die Form deines eigenen Denkens, mit eingezeichneten Brücken.
Ein Ordnerbaum beantwortet "wo hab ich's hingelegt". Ein Wissensgraph beantwortet "womit hängt es zusammen" — und für Beratung ist die zweite Frage die abrechenbare.
Deshalb reicht eine flache Bookmark-Liste, oder selbst ein sauberes Wiki, nicht aus. Eine Liste ist eindimensional. Eine Wiki-Seite ist tief, aber lokal. Der Graph ist das, was Regulierung, Markt und Deal nebeneinander auf den Schirm bringt — weil dein Lesen sie schon nebeneinander gelegt hat. Du hast es nur nie gesehen.
Such nach Bedeutung, dann folge den Fäden
Du navigierst den Graphen nicht, indem du dich an Stichwörter erinnerst. Du navigierst ihn über Bedeutung.
Tippe ein Thema — "Lieferketten-Resilienz", "Geschäftsführerhaftung unter dem neuen Regime", was auch immer dich gerade beschäftigt — und verwandte Konzepte leuchten auf, selbst wenn dein gespeichertes Material diese exakten Wörter nie benutzt hat. Genau das ist der Unterschied zwischen semantischer Suche und Strg-F. Du matchst keine Zeichenketten, du matchst Ideen. Das Konzept, an das du dich halb erinnerst, taucht neben vier anderen auf, von denen du vergessen hattest, dass sie zusammengehören.
Klick einen Knoten an, und seine Wiki-Seite öffnet sich — destilliert, zitiert, mit intakten Quell-Links. Der Graph ist also keine hübsche Visualisierung, die in der Sackgasse endet. Jeder Knoten ist eine Tür in das tatsächliche Lesen darunter, rückverfolgbar bis dahin, wo du es gefunden hast.
Für die Momente, in denen du von unten nach oben arbeitest statt von oben nach unten, gibt es eine zweite Ansicht: die Bookmark-Topic-Map. Sie clustert deine rohen Saves nach Ähnlichkeit, sodass sich ein Monat verstreutes Lesen in eine Handvoll Themen auflöst, die du auf einen Blick siehst. Der Graph zeigt dir, wie Konzepte zusammenhängen; die Topic-Map zeigt dir, was du zuletzt tatsächlich gelesen hast. Du wirst beides benutzen — die Map zur Bestandsaufnahme, den Graphen, um einem Faden nachzugehen.
Warum das für die Arbeit zählt, die du abrechnest
Beratung und Recherche sind Nachbarschafts-Geschäfte. Der Wert, den du lieferst, ist selten ein einzelner Fakt — es ist die Verbindung, die sonst niemand im Raum gezogen hat, weil sonst niemand die vier Dinge gelesen hat, die du gelesen hast. Das Problem: Dein eigenes Hirn ist ein miserabler Index. Du hast es gelesen, du weißt, dass du es gelesen hast, und du findest es nicht.
Ein Wissensgraph löst das Index-Problem und das Nachbarschafts-Problem auf einmal. Das Lesen, das du schon erledigt hast, wird zu einem Asset, das sich verzinst, statt zu einem Stapel, der verfällt. Je mehr du speicherst, desto dichter der Graph, desto öfter landet eine Suche auf einer Verbindung, die du wirklich vergessen hattest — und desto schneller schreibt sich das nächste Briefing von selbst.
Wenn du Tools kennst, bei denen der Graph die Arbeit ist — bei denen man [[Backlinks]] von Hand verdrahtet —, kennst du die Steuer, die das kostet. Piths Graph ist ein Nebenprodukt des Lesens, kein Zweitjob. (Den Kontrast vertiefen wir in Pith vs. Obsidian.)
Deine Daten liegen in Frankfurt, in der EU — was für die Regulierten und die Vorsichtigen keine Fußnote ist.
Das Lesen hast du längst erledigt. Pith sorgt nur dafür, dass du siehst, womit es zusammenhängt.
FAQ
Wie unterscheidet sich der Wissensgraph von Ordnern oder Tags?
Ordner und Tags legen jedes Element an genau einer Stelle ab. Der Graph speichert Beziehungen: Ein Konzept ist mit jedem anderen verbunden, mit dem es in deinem Lesen gemeinsam auftaucht. So siehst du, wie Markt, Regulierung und Deal zusammenhängen — Nachbarschaften, die ein Ordnerbaum verbirgt.
Muss ich den Graphen selbst bauen oder pflegen?
Nein. Du speicherst, was du liest. Pith destilliert die Konzepte, schreibt die zitierten Wiki-Seiten und verdrahtet die Verbindungen automatisch. Der Graph ist ein Nebenprodukt des Lesens, kein Zweitjob.