Your reading, as one knowledge graph
You don't read in silos, so why store reading in them? Pith distils everything you save into one knowledge graph — and the adjacencies it surfaces are where the insight lives.
In short
Pith builds a cited wiki from what you bookmark, then connects the distilled concepts into one knowledge graph. You search it semantically — type a theme and related concepts light up even when the exact word never appears — and click any node to open its wiki page.
The team behind Pith Lab
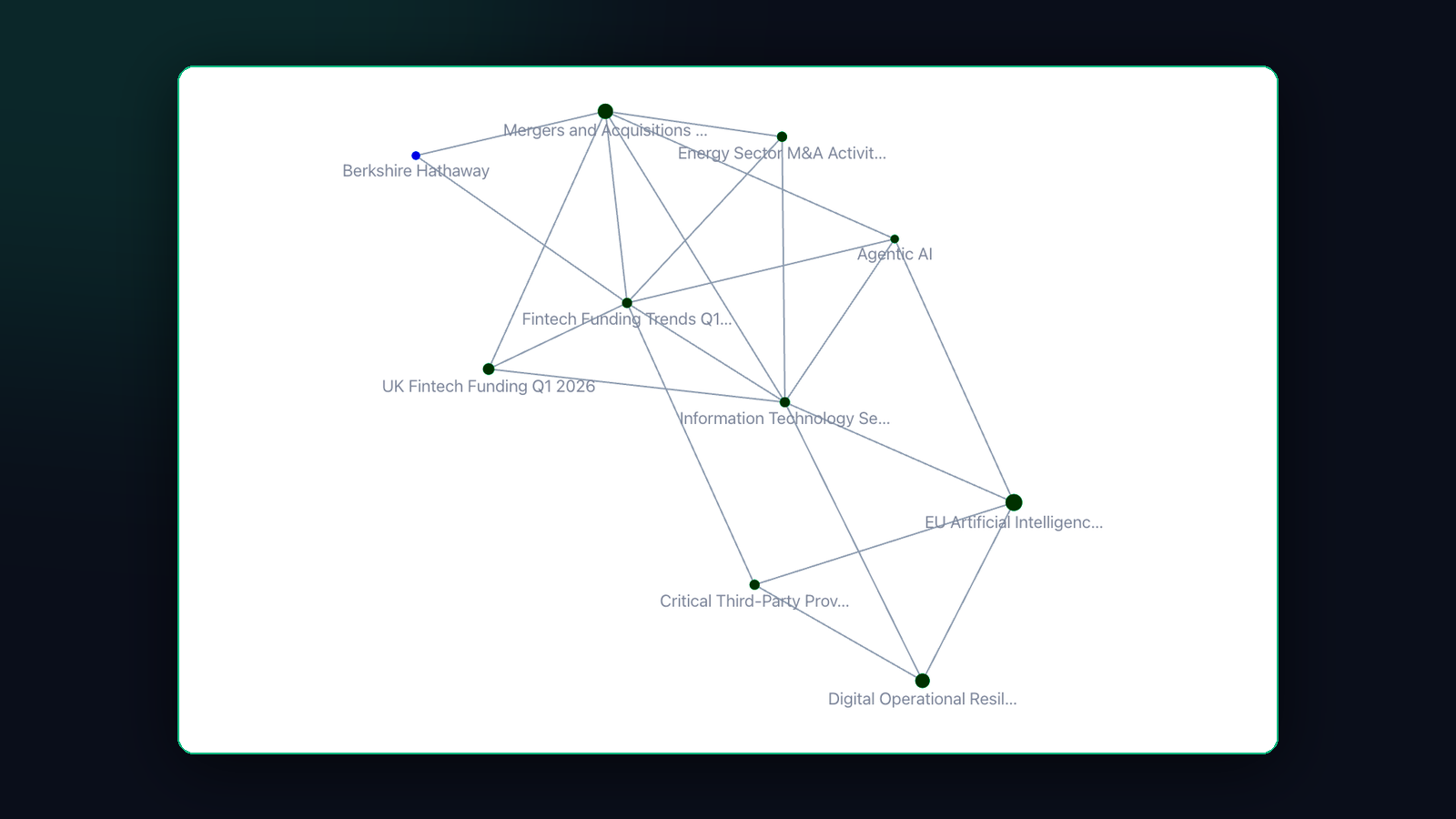
You don't read in one lane. In a single week you'll read a regulatory consultation, a competitor's earnings call, a market sizing for an unrelated sector, and a long memo about a deal that may or may not happen. Then you file each one somewhere — a folder, a tag, a tab you never reopen — and the connections between them quietly evaporate.
That's the loss. Not the reading. The adjacencies.
The whole point of having read widely is that two things you read three weeks apart turn out to be the same thing. A client's new market is governed by the regulation you skimmed for a different engagement. The deal you're sizing has a precedent buried in a sector scan you saved and forgot. You can only act on that if you can see it.
The graph is the connections you'd otherwise miss
Here's how Pith works. You bookmark what you read — three seconds, no filing decision. Pith distils each save into concepts and assembles them into a cited wiki you didn't have to write. Then it does the part that matters: it connects those concepts into one knowledge graph.
Not a graph per project. Not a graph per client. One graph, across everything you've read.
Each node is a concept. Each edge is a real co-occurrence — these two ideas showed up together in your actual reading, not in some generic ontology. So when you open the graph, you're not looking at a tag cloud. You're looking at the shape of your own thinking, with the bridges drawn in.
A folder tree answers "where did I put it." A knowledge graph answers "what does it connect to" — and for a consultant, the second question is the billable one.
This is why a flat list of bookmarks, or even a tidy wiki, isn't enough. A list is one-dimensional. A wiki page is deep but local. The graph is what lets a regulation, a market, and a deal sit next to each other on screen because your reading already put them next to each other — you just never saw it.
Search it by meaning, then follow the threads
You don't navigate the graph by remembering keywords. You navigate it by meaning.
Type a theme — "supply-chain resilience," "founder liability under the new regime," whatever you're actually thinking about — and related concepts light up even when your saved material never used those exact words. That's the difference between semantic search and Ctrl-F. You're not matching strings; you're matching ideas. The concept you half-remember surfaces next to four you'd forgotten were related.
Click any node and its wiki page opens — distilled, cited, with the source links intact. So the graph isn't a pretty visualisation that dead-ends. Every node is a door into the actual reading underneath, traceable back to where you found it.
There's a second view for when you're working bottom-up rather than top-down: the bookmark topic map. It clusters your raw saves by similarity, so a month of scattered reading resolves into a handful of themes you can see at a glance. The graph shows you how concepts connect; the topic map shows you what you've actually been reading lately. You'll use both — the map to take stock, the graph to chase a thread.
Why this matters for the work you bill for
Consulting and research are adjacency businesses. The value you add is rarely a single fact — it's the connection nobody else in the room made, because nobody else read the four things you read. The problem is that your own brain is a terrible index. You read it, you know you read it, you cannot find it.
A knowledge graph fixes the index problem and the adjacency problem at once. The reading you've already done becomes an asset that compounds instead of a pile that decays. The more you save, the denser the graph, the more often a search lands on a connection you'd genuinely forgotten — and the faster the next briefing writes itself.
If you've used tools where the graph is the work — manually wiring [[backlinks]] by hand — you know the tax that imposes. Pith's graph is a by-product of reading, not a second job. (We go deeper on that contrast in Pith vs Obsidian.)
Your data lives in Frankfurt, in the EU, which for the regulated and the cautious is not a footnote.
You already did the reading. Pith just makes sure you can see what it connects to.
FAQ
How is the knowledge graph different from a folder or tag system?
Folders and tags store each item in one place. The graph stores relationships: a concept connects to every other concept it co-occurs with across your reading, so you see how a market, a regulation, and a deal link up — adjacencies a folder tree hides.
Do I have to build or maintain the graph myself?
No. You bookmark what you read. Pith distils the concepts, writes the cited wiki pages, and wires the connections automatically. The graph is a by-product of reading, not a second job.